Query caching
Learn more about caching query results to increase app performance.
Retool provides support for caching query results, allowing users to better manage their data. By caching query results, you can speed up the performance and load speeds of an application.
Query caching is most helpful in cases of:
- Expensive database queries on slow updating datasets. Running an aggregation query over months of event data can be expensive and slow. Caching the results of these queries means expensive queries run less frequently and results load faster.
- Database or API queries that return a very large amount of results. Querying your database for 5,000+ rows of data can be very resource-intensive for your application. Caching the results can free up the time and resources that the query would originally have used.
Caching is not recommended for transactional queries. If your data is updating in realtime, via an upstream source or Retool app actions, caching increases the likelihood that your users will see stale, incorrect data.
How query caching works
When enabled, queries are cached server-side inside of the Retool database connector. Whenever a query is run, Retool checks the inputs and cache duration lifespan to determine whether to return cached results or route the query to your database.
If the exact same query is run using the same inputs within the Cache duration lifespan, the cached result is returned rather than querying the resource. If the cache lifespan for the specific query and input combination has expired or the cache has been invalidated, the query is routed to the resource.
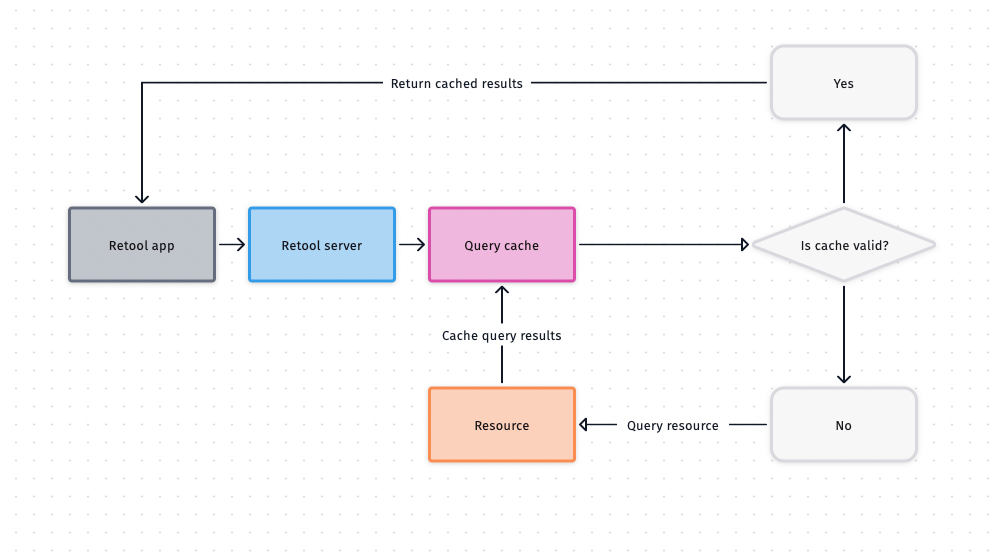
By default, the cache is shared across users in the same organization. If two users run a query with the same requests—even with different auth tokens—the cached results are still returned.
Administrators can disable Cache queries across all users in your organization's Advanced settings to perform caching on a per-user basis instead.

Use query caching
Caching is set at the query level. Check Cache the results of this query in the Advanced tab of the query editor to turn on caching for a specific query. You must specify the number of seconds the query should be cached for (e.g., 3600 for one hour).
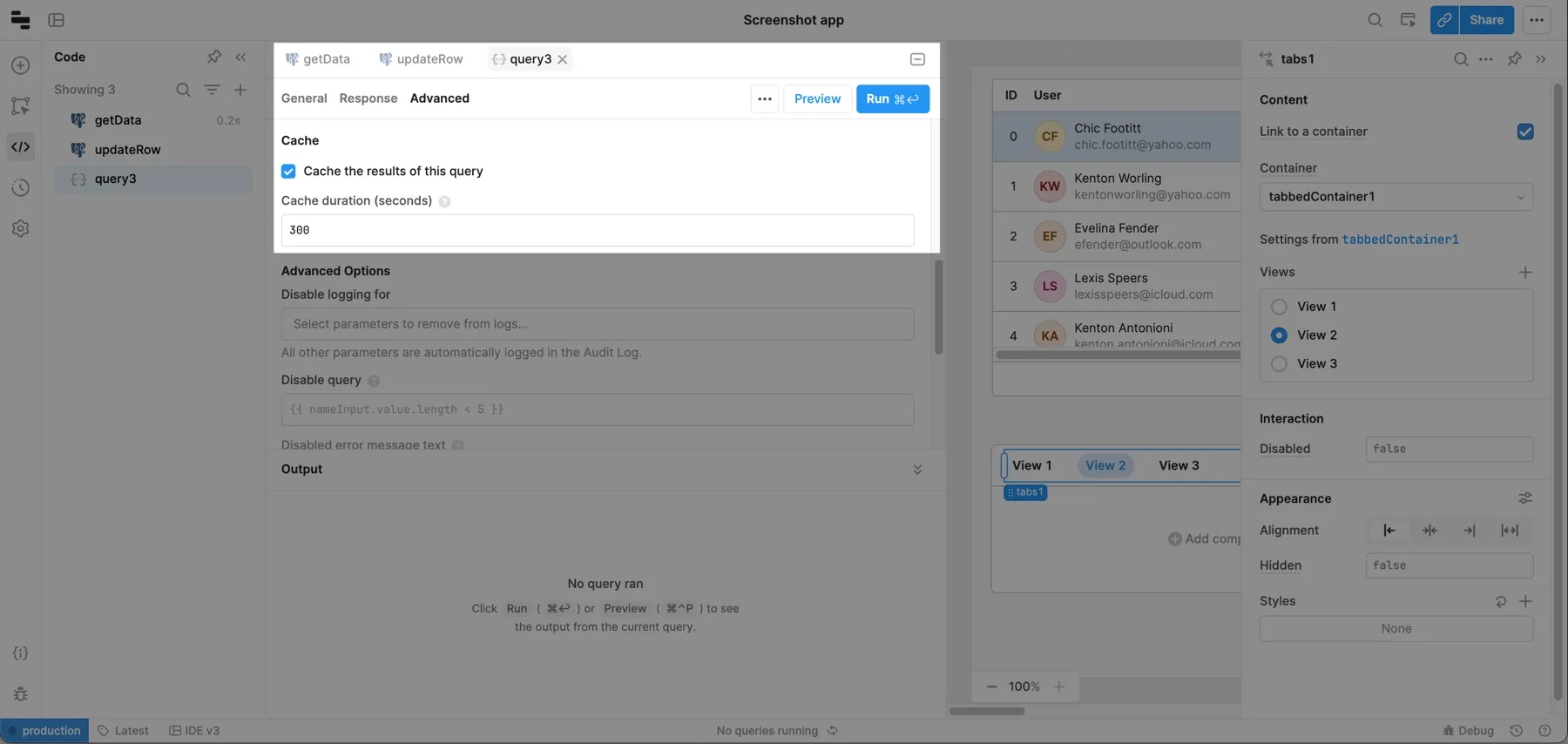
Monitor the cache
You can use cache-related query properties to determine if a cached result was used, when the cached results were fetched from the resource and whether the next run will hit the cache.
| Property | Description |
|---|---|
query.servedFromCache | Boolean indicating whether query results were returned from cache. |
query.lastReceivedFromResourceAt | Unix timestamp in milliseconds when the query result was last received from the resource. |
query.cacheKeyTtl | The cache duration in seconds, referenced as the TTL (Time to Live) time. If query.lastReceivedFromResourceAt + (query.cacheKeyTtl * 1000) > Date.now() the next run will query the resource and cache fresh results. |
Invalidate the cache
You can use the invalidateCache() JavaScript method to invalidate the cache before the TTL runs out. You can also use event handlers to invalidate the cache by selecting the Control query action and Clear cache method.
Configure the cache for self-hosted instances
Redis caching
Without a Redis-connected resource, the cache is stored on the local file system of the Retool server. The cache can be invalidated if the Retool worker stops running which may cause in-memory and file system caches to be wiped.
With a Redis-connected resource, the cache is stored within Redis instead of the file system, and is automatically set up once connected. This enables greater flexibility around caching behavior and also gives you visibility on how data is stored.
Refer to our documentation on environment variables to view Redis-specific variable information. Once set up and connected, Retool automatically leverages the Redis instance as a caching layer for queries with caching enabled.
Connect Retool to Redis on AWS ElastiCache
- Log in to the AWS console for your appropriate region.
- Create an Amazon ElastiCache cluster.
- Choose Redis as your cluster engine. Do not enable cluster mode. Cluster mode will handle spreading keys across multiple shards. By default, the Redis shard should be able to store 13GB of data which is substantial.

- Enter the name and description of the cluster. Leave the rest of the fields as-is.
- Port: 6379 by default. A custom port can be specified as an additional layer of protection though for most use cases is not required.
- Node type: Large by default. Automatically set to be able to store 13GB of data.
- Multi-AZ: True by default. Multi-AZ is especially useful when we have strong high availability requirements for the use case (many users, critical workflow). Redis is usually highly available even without this feature as long as we replicate to at least 2 nodes.
- Number of Replicas: 2 by default. This will replicate the data into 2 other nodes as well.
In the event that the primary node for the cluster fails, Multi-AZ ensures that it follows protocol to assign a new primary immediately (taking the read replica with the fastest recorded latency times). For small or medium use cases, or for testing purposes, you can set this to false. You can change this retroactively by modifying the replication group.
- Advanced Redis Settings: Ensure we are under the same VPC for this Redis instance as the instance where Retool is deployed. Otherwise, the two will not be able to communicate. For Multi-AZs, we need to provide two subnets.

-
Data Management: Enable automatic backups. This is optional but highly recommended. If you experience unexplained issues, you can retrieve the previous backup.
-
Create Cluster.
Monitor the Redis instance
- Log in to the Retool instance (or create a new one in the same VPC as both Retool and Redis) and enter the following commands.
sudo wget http://download.redis.io/redis-stable.tar.gz
sudo tar xvzf redis-stable.tar.gz
cd redis-stable
sudo CC=clang make BUILD_TLS=yes # only if TLS is enabled
- Read the Redis instance by running either of the two commands below. The cluster endpoint should be the reader hostname. The port number should be the port number entered above (by default, it is 6379).
# If no password is setup, run:
redis-cli -h <cluster-endpoint> -c -p <port number>
# Otherwise...
redis-cli -h <cluster-endpoint> --tls -a <your-password> -p <port number>
- Once in the Redis CLI, run some
getandsetcommands to verify expected behavior. Running theINFOcommand displays stats for the Redis cluster.