Disaster Recovery Recommendations
Disaster Recovery focuses on creating resilient architectures that are able to return to operation at a predefined time after temporary or permanent outage has occurred. A temporary outage historically could range from minutes to hours depending on the complexity of the event. A permanent outage in comparison could be the result of mechanical failures (e.g. cooling), fires, floods, earthquakes to name a few. In these circumstances the data center may be permanently offline. Two key metrics that help inform architects of the business expectation to return to service with a predefined loss of data are Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
Recovery Time Objective
This metric identifies how soon after the outage event the application is expected to be available for its consumers. For example a RTO of 1 hour expects the backup application to be available an hour or less from when the event occurred. If the event occurred at 1:15 pm ET, the application needs to be up and running at 2:15 pm ET or sooner.
Recovery Point Objective
This metric identifies a point in time that data can be recovered prior to the event. For example an RPO of 30 minutes means that the application data needs to be recoverable within 30 minutes or less of when the event occurred. If the event occurred at 1:15 pm ET, data from 12:45 pm ET - 1:15 pm ET needs to be available in the recovered application.
AWS Disaster Recovery Primer
The following whitepaper provides an in depth discussion on AWS Disaster Recovery considerations and should be examined before proceeding to the next section.
The important image that helps identify the DR strategy is shown below and this helps guide solutions architects on the necessary architecture / services that a customer employs to support the RTO/RPO. The following example will focus on Real-time / Zero downtime, the most extreme case.
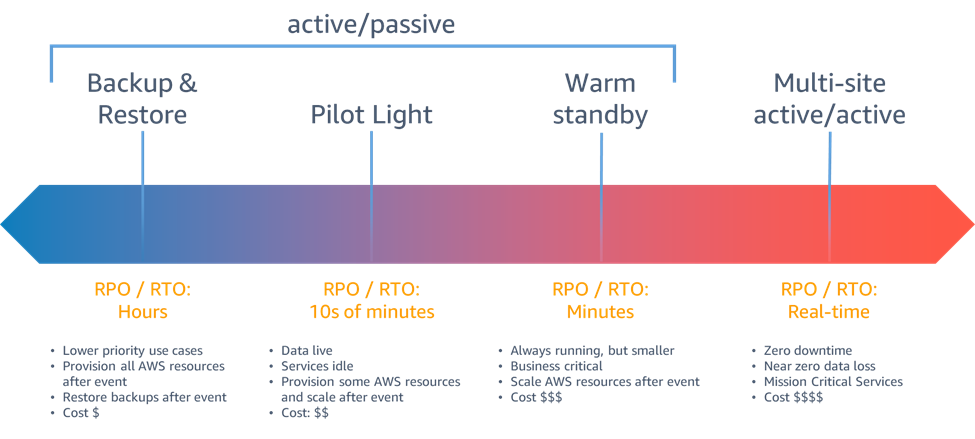
Retool Disaster Recovery Examples
RPO / RTO Real-time Use Case
The following example will focus on RPO / RTO of Real-time which requires a Multi-site active/active configuration. This means that the Retool setup runs actively in two separate regions and a synchronous replication between the primary region and secondary region has been configured. It also requires that all dependent data services that feed the Retool application are also configured to support the DR requirement. For example if an Amazon DynamoDB database is leveraged as a data service in the primary region, then use of Global Tables should be considered to span the data across multiple regions in the event of an outage.
Docker Compose
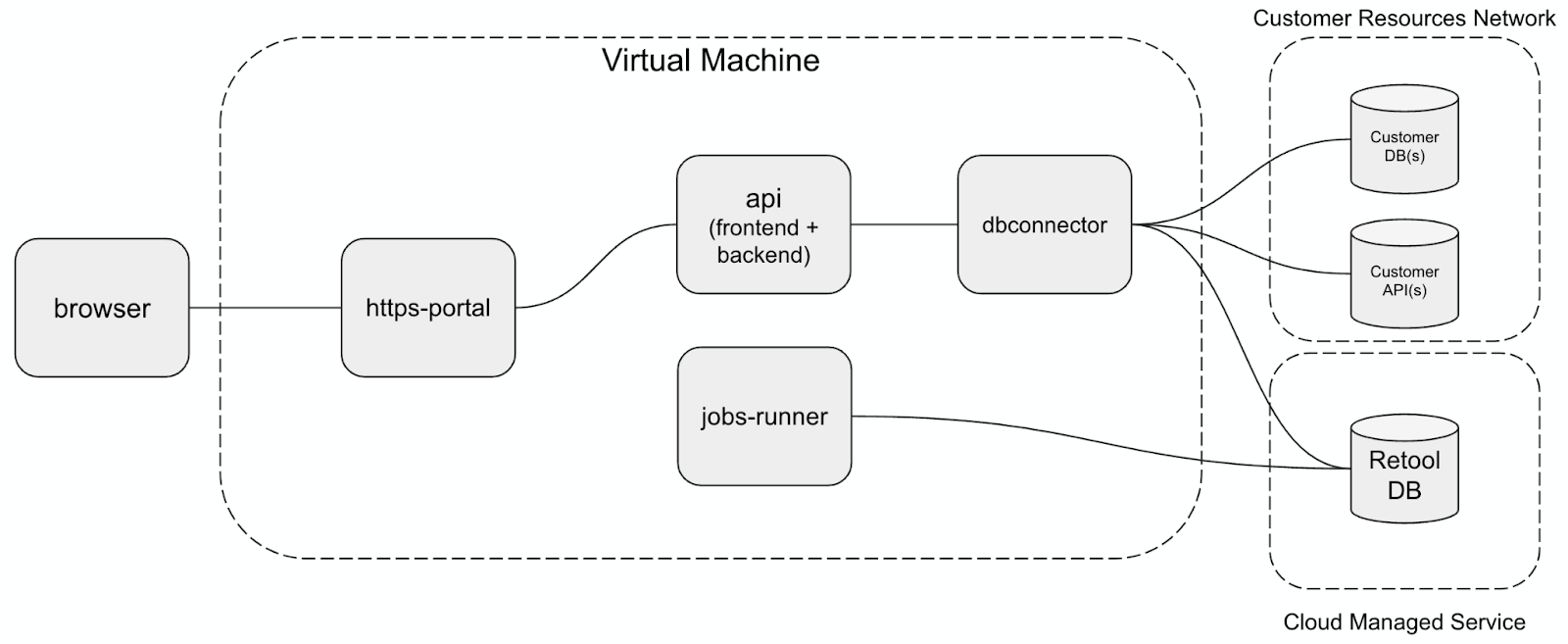
The base architecture of a Docker Compose installation is shown in the following figure running in a single region on a single EC2 instance. Traffic flows from left to right where the individual Docker containers are managed by Docker Compose. The Customer Resource Network represents data that the Retool application is consuming (e.g. Amazon RDS, Amazon DynamoDB etc). The Cloud Managed Service is the Retool database running in Amazon Aurora for example and is storing the apps, configuration and other important Retool data.
If we now zoom out and consider this architecture in two different regions, to support a regional outage event, we have a Primary Region (e.g. us-east-2) and a Secondary Region (e.g. us-west-2) and a DB replication connection between regions.This can be accomplished via Amazon Aurora Global Database as described here. DNS Services act as the gateway to the primary and secondary region. Using Amazon Route53 failover routing policy, health checks are performed regularly on the primary instance by accessing a health endpoint using this approach. When the failover policy health checks are breached and fail to return a success code, the DNS Services switches traffic to the Secondary Region.
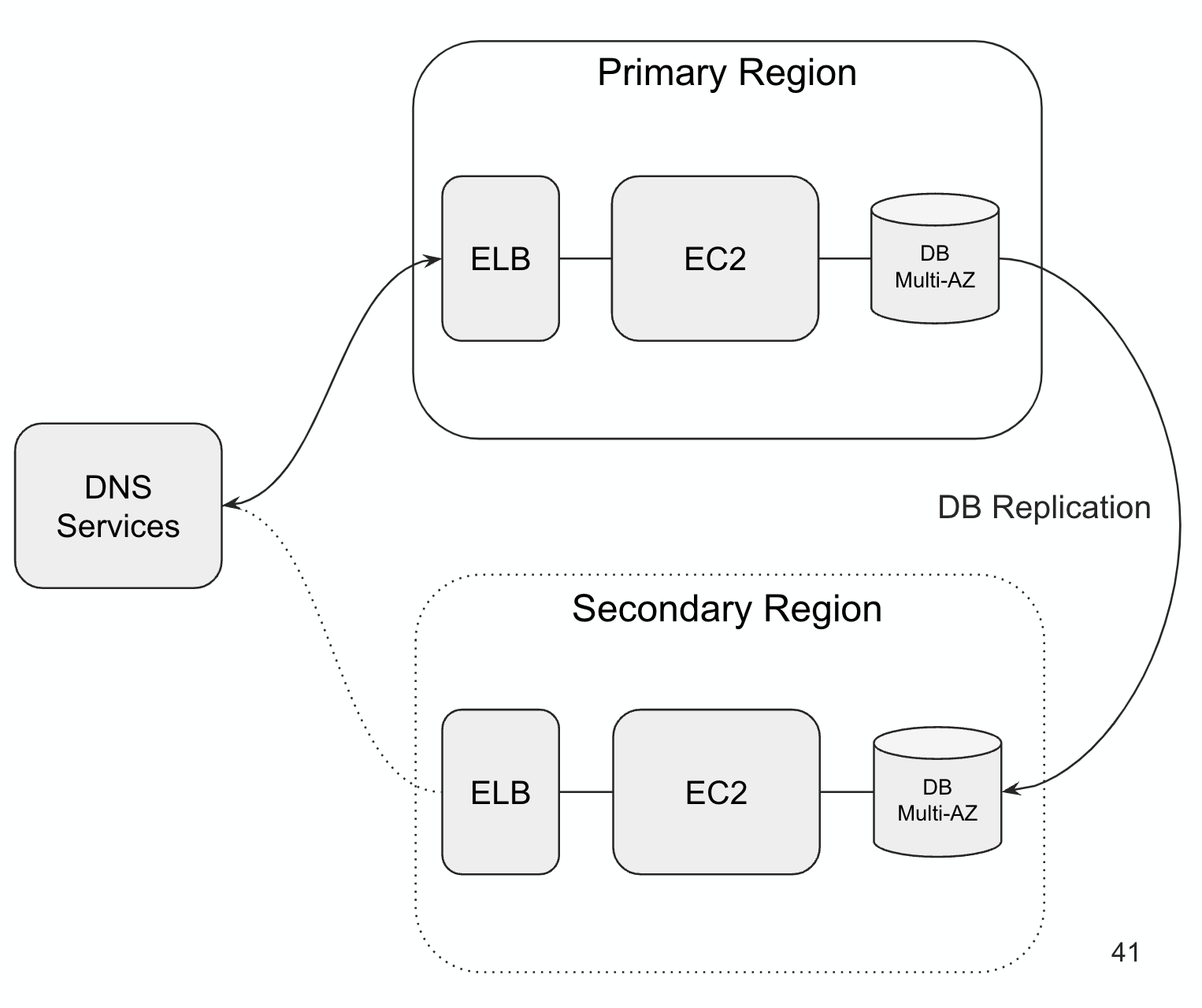
NOTE: Similar strategy to provide equivalent Customer Resources needs to be architected.
Kubernetes
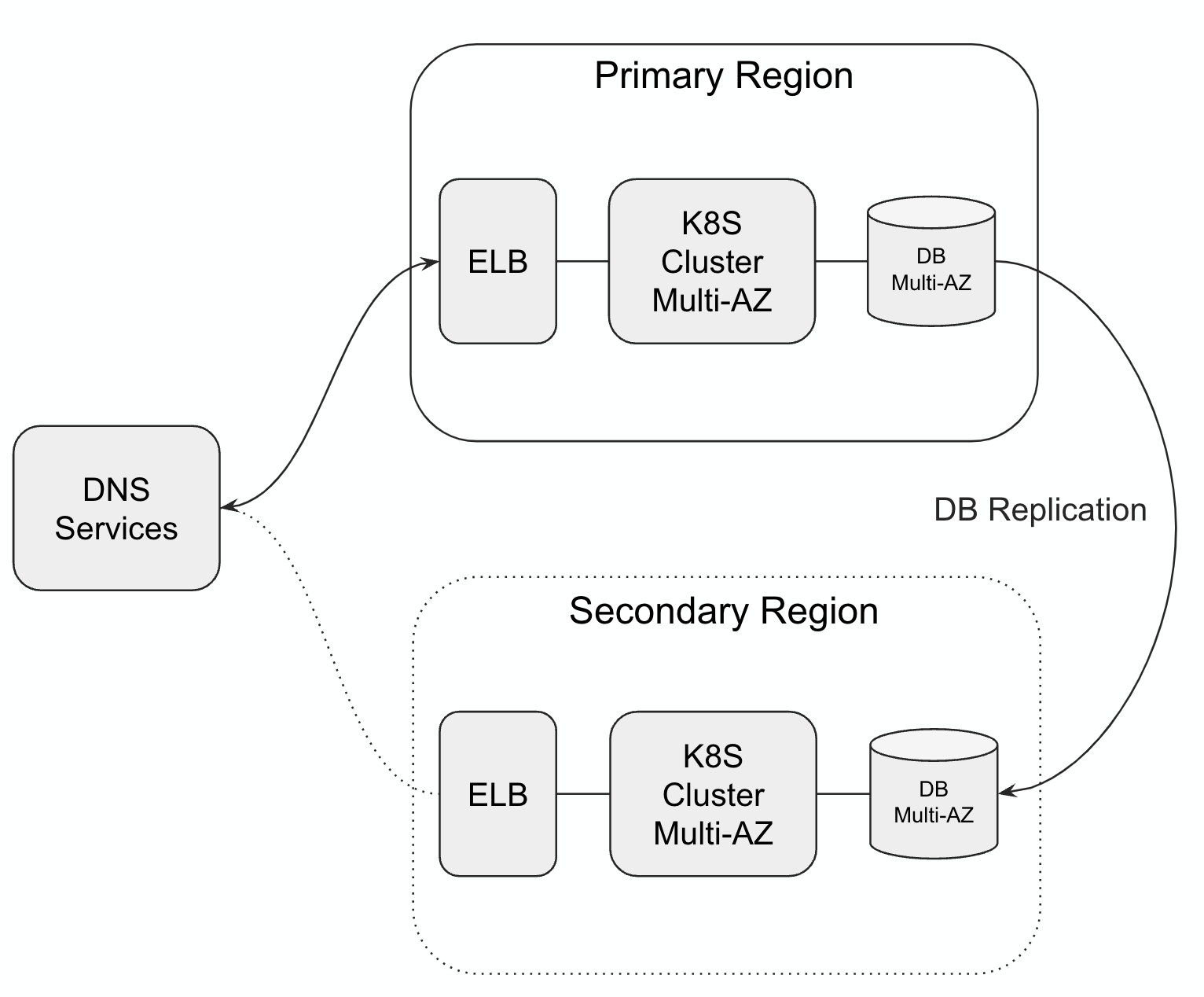
Kubernetes follows a similar model where the Retool DB replication is the most important activity. Similar to the previous example, DNS Services are configured with Failover Routing and health checks to determine when to switch to the secondary region.
RPO / RTO Hours Backup and Restore Use Case
In this example, RPO / RTO are defined in hours, allowing the recovery process to consider cheaper alternatives to the Active-Active example. In this use case, the key component is defining a database snapshot mechanism that is able to support the RPO requirement. Amazon RDS provides out of the box support for Snapshots during the daily maintenance window as described here. The database snapshot should be copied to a secondary region and stored in Amazon S3. In the secondary region, the customer will reinstall either the Docker-compose, ECS or EKS installation using a combination of Infrastructure as Code(IaC) to create the underlying network, compute, storage and security. Once this has been completed, the Retool platform is installed either via Docker Compose manifest, Kubernetes manifest or Helm package manager. This activity when used in combination with IaC can occur within 1-2 hours.