Retool Agent Testing
The following lab covers how to test Agents using Logs, Evals, and Datasets.
Requirements
It is recommended that you complete the following courses in Retool University to understand terminology and the Retool Agents product. These are available in the AI Fundamentals Path and Adv. Developer Path, or individually as courses.
- AI Agent Concepts Course
- Retool Agents Course
Prerequisites
This lab leverages the Delivery Agent Example for generating a Dataset and Eval(s). To complete this lab, you will first need to follow the Delivery Agent instructions to create a working sample to test.
Terminology
What is a dataset and eval?
Within a Retool Agent, builders have access to datasets and evaluations. Unlike traditional deterministic software, where you may have written a Unit Test, Integrated Test, etc, Agents require additional validation that can capture their non-deterministic results. The following image shows where, within an Agent, you can access Logs, Evals, and Datasets.

Logs
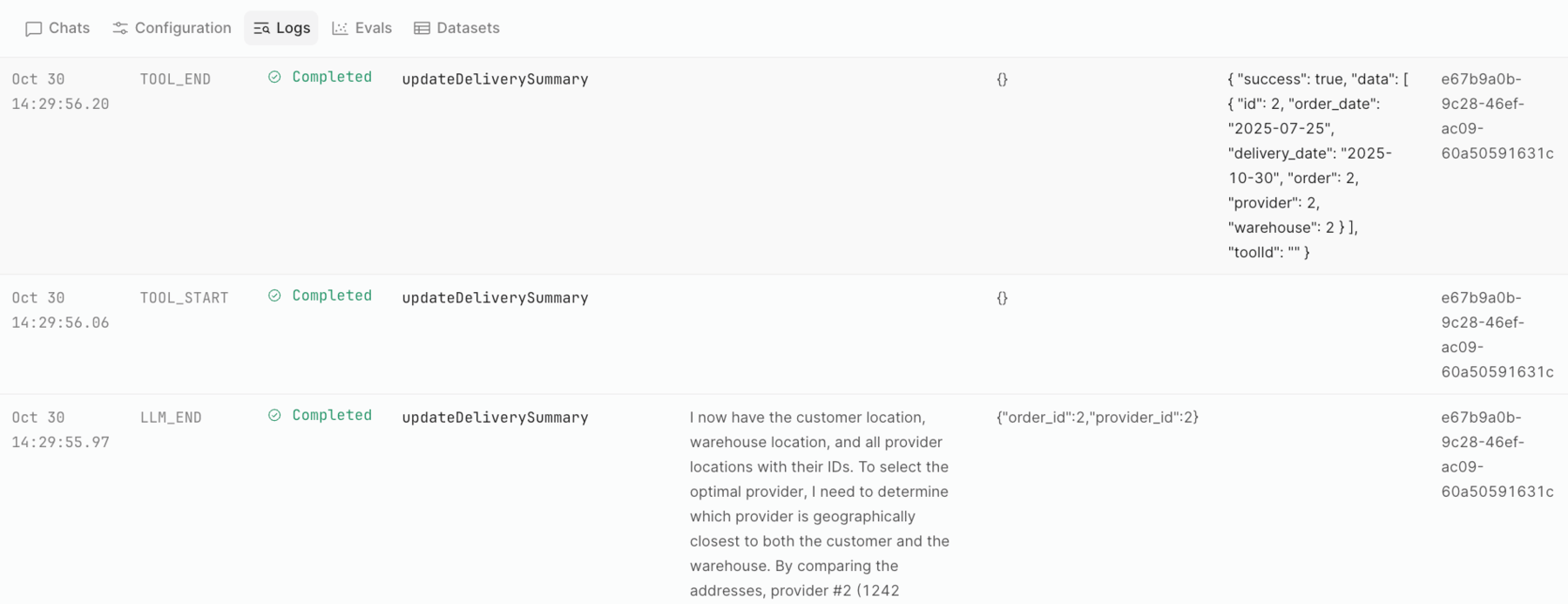
Logs capture the running execution output of an agent. The following image displays the information available to understand how the Agent is reasoning, including its inputs, outputs, tool selection, and more.
Dataset
In a Retool Agent, the Dataset is where an AI Builder can author test cases for validating a tool call or final answer of an agent. The following image shows a single test case within the Delivery Agent Validation Dataset.

Tool calls refer to the interactions an agent has with its environment. They can be out-of-the-box tools, such as Email or Web search, or custom tools, leveraging Retool Functions. The following provides a simplified example of a test case designed to determine which custom tool is being used.
When I invoked the agent, did it first use the getStockPrice tool?
Where tool call test cases focus on determining if the agent properly employed the tools available to it, a final answer test case focuses on the output at a specific point in the Agent's processing. In general terms, the following question represents a final answer.
When I invoked the agent, did I get a total of $12.25?
Evaluation (Eval)
An evaluation, or eval, is when the AI Builder runs the Dataset and its test case(s) against the agent. An eval run provides a result between 0 and 100 to indicate the overall probability of success. Unlike traditional software, which focuses on conditional logic (e.g., if/then/else if/else) to return a binary response (0 or 1, true or false, etc.), Agent responses can be more varied and do not fit into a simple true or false result.
Steps
The following steps will guide you through a straightforward process to create your first test case to evaluate the final answer of an agent.
Create Dataset
The dataset represents a collection of similar test cases focused on examining a specific Agent behavior.
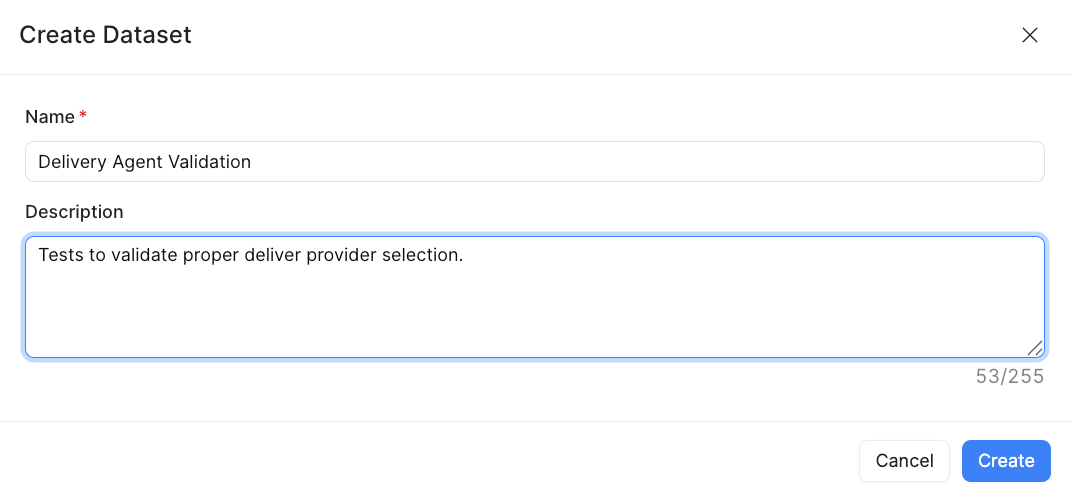
- To create a dataset, edit the Agent in question and select Dataset > Add Dataset.
- Add a name and description and select Create.
Create Test Case
Next, we need to create one or more test cases to evaluate the results of the delivery agent. We will use the Chat interface to run the delivery agent and then generate a testcase for the dataset.
- Select Chat. Enter the following chat into the interface:
Please set up delivery for order #2
- This will initiate the Agent. Wait until it has completed.
- At the bottom of the agent interaction, select (…) in the Chat interface as shown below:
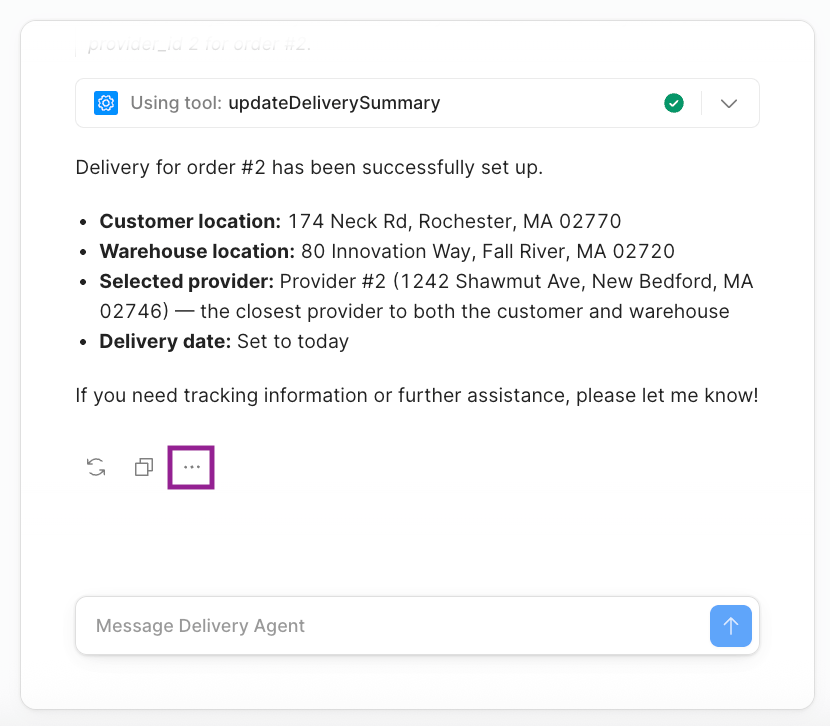
- This will make the following menu appear, select + Add to Eval dataset.

- The following dialog will appear, providing an overview of the test case.
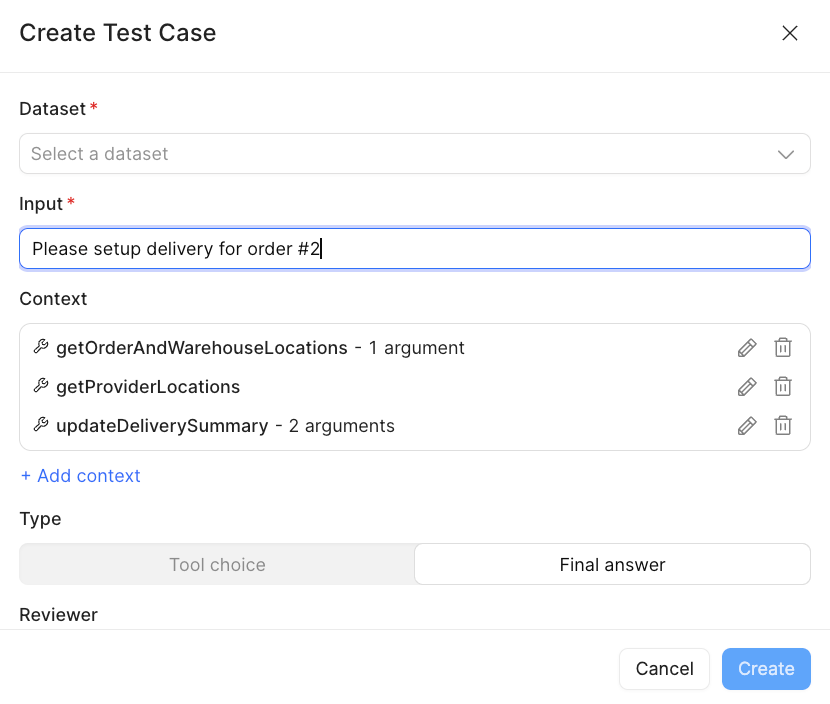
INFO: For the Eval run to succeed, it requires context that occurs prior to the final answer. Under Context, the individual Tool calls are identified, along with their arguments, captured from this Chat session. If we scroll down in the interface, you will see that the Type is Final answer and identifies the Reviewer. The following image shows that the Reviewer is set to LLM as a judge. This is one of the options to assert what the result was and how close it matches our expected behavior… remember 0 -> 100 not true or false.
- Select the Dataset,
Delivery Agent Validation. Then select Create.
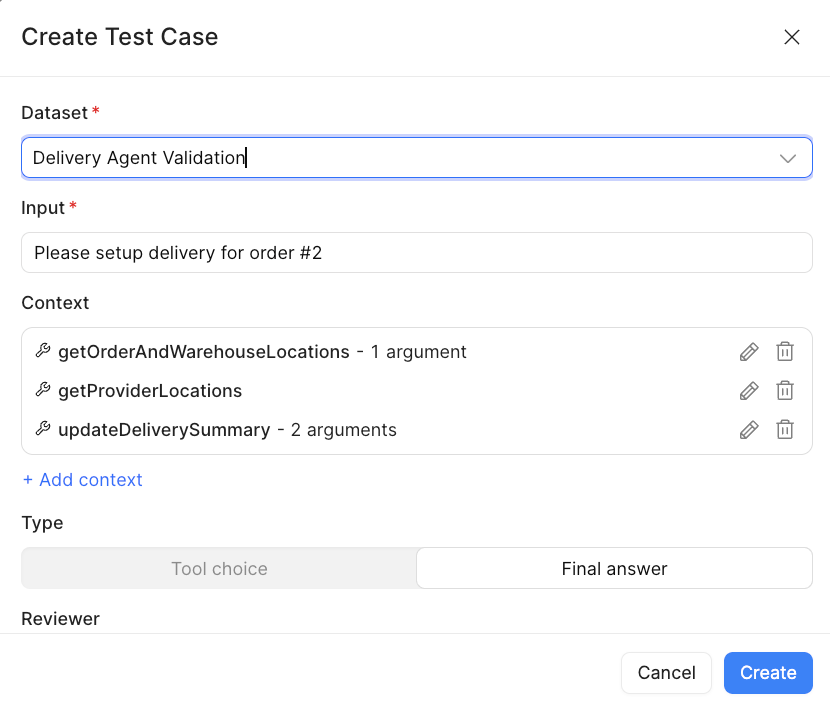
This adds a test case to the dataset we specified as shown below.

Create Eval
Once we have a dataset with a test case, we can then move to running it. This is referred to as an Evaluation or Eval.
- Exit out of the Datasets by selecting the left arrow.
- Select Evals and a dialog with no evaluations will appear.

- Select Run and populate the
New eval rundialog, identifying the dataset, and enter a run name. Then select Run eval(1).

- The eval will execute and display a result in the
Average scorecolumn. This value can range from 0 to 100 so values like 25, 33, 50 etc. are valid. A value of 100 in this case indicates that the result matched the expected value.

- Select
Delivery of order #2to examine more details of the evaluation. This will exposeTest Case Details. You can review the details to see what occurred during the eval.
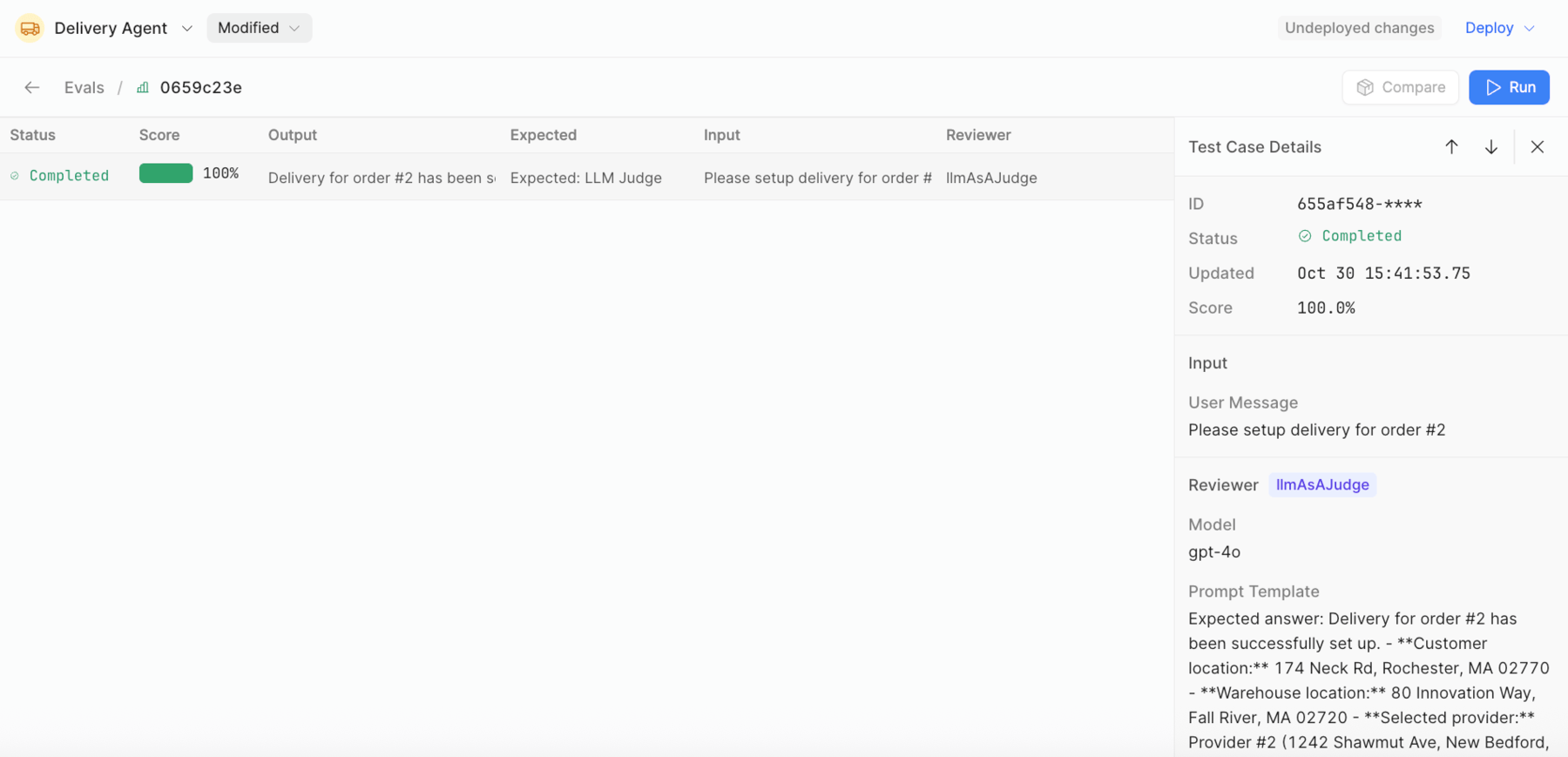
Examine result
AI Builders can review evals to understand whether an agent is improving or degrading for specific test cases. Evals and Logs provide information that is relevant for understanding the behavior relative to inputs and outputs.
Evals
Test case details provide a UUID, status, date and score as shown in the following image:

Input provides the input provided to the agent.

Reviewer provides the Model being employed and the prompt used to evaluate the result.

Output & Scoring focuses on a value of 0 to 100, defines the Rationale that is being used to evaluate the result and the Agent output. In this example an LLM as a Judge is being employed to reason whether the result is close or far away from the criteria provided.

Logs
In addition to Evals, we can examine the runtime logs and look more closely at the input and outputs for each step in the Agent’s reasoning processing and tool use. The following table provides an overview of the various states that are displayed in the agent log:
| Action | Description |
|---|---|
| AGENT_START | The agent has begun processing the request. |
| AGENT_END | The agent has completed processing the request. |
| TOOL_START | The agent has selected a tool. |
| TOOL_END | The agent has results from the tool. |
| LLM_START | The agent is starting to run its reasoning. |
| LLM_END | The agent has completed its reasoning and will not execute its next determined step. |
The following examples illustrate how a better understanding of the ordering of steps, the agent's reasoning, the results of tool calls, and more can be achieved.
LLM_END Example
The following excerpt shows a snippet of the LLM_END processing that occurred, determining which tool was to be called, getOrderAndWarehouseLocations, and the input that it would provide to it,
{“order_id” : 2}
TOOL_END Example
The following excerpt shows a snippet of the TOOL_END processing that occurred as the getOrderAndWarehouseLocations tool was executed. This shows the result that was retrieved when executed.
Reviewer
As you work on developing test cases and specifically when determining Final answer, there are a number of reviewer selections.
- To access these select + Add Test Case.
- Select Final answer, and select + Add Reviewer. The following dialog appears allowing you to select
Built-in / Programmatic,Built-in / LLM as a judge.
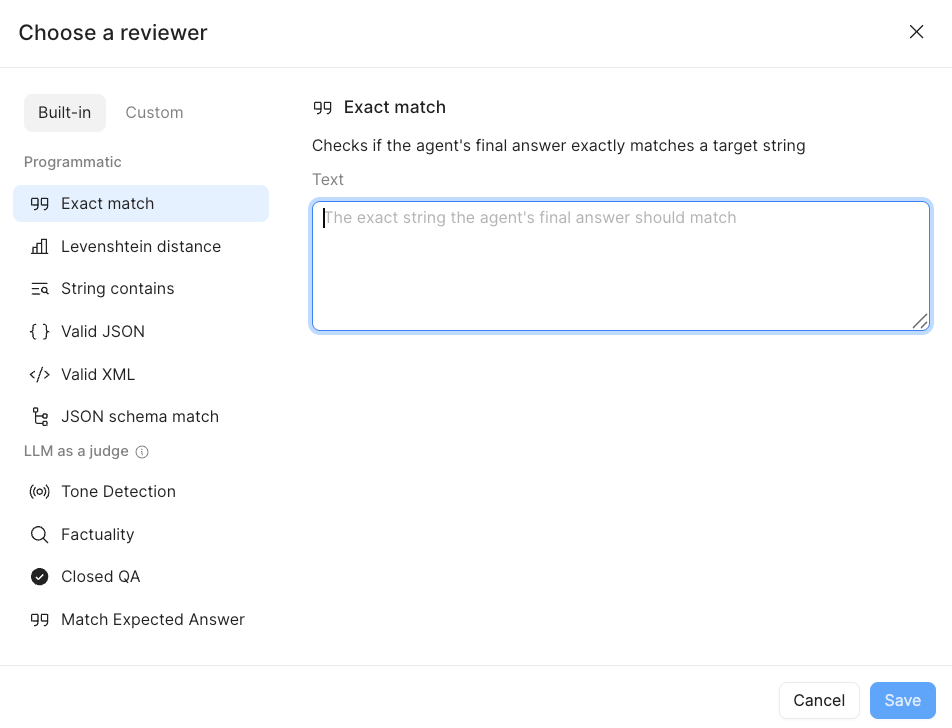
NOTE: Programmatic options provide a cost-effective way to examine the Final answer output and either match, look for strings, look for similarity, or response validity (e.g. Valid JSON, Valid XML). LLM as a judge will invoke a configured model incurring costs. You can leverage the Agent Monitoring dashboard to examine agent run costs / token quantity.
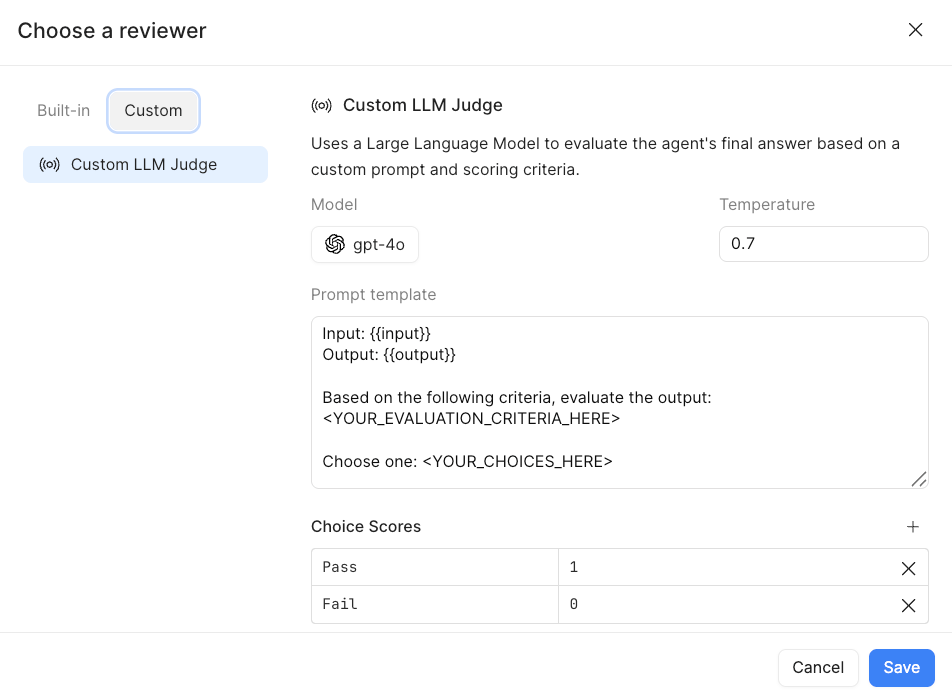
- You can also select Custom and leverage the
Custom LLM Judge. This allows the AI Builder to specify theModel,Temperature(creativity),Prompt templateandChoice Scoresthat you are evaluating.
Summary
This lab provided an introduction to Retool Agent’s Dataset, Evals, and Logs. This functionality is a critical cornerstone in establishing the observability of what an agent is doing and whether it is succeeding or deviating from expected behavior. Test cases should align with the expected behavior defined by individuals closest to the process/use case.